
Since microservices have gotten so much buzz in the last few years, I suppose it was probably only a matter of time before someone got the big idea to make microservices, even smaller. The result is something called a nanoservice. A nanoservice is like a microservice, except smaller, and more focused on a single, logical task.
Nanoservices have all the advantages of microservices – flexibility, scalability, the ability to be designed, maintained, built, and deployed independently, etc. I suppose they also suffer from all the same drawbacks – more complex overall architecture, network latency, the need for load balancing, more points of failure, etc.
Still, if you’ve already gone down the microservice rabbit hole, I suppose adding a few nanoservices might be something to consider. Personally, I’ve played with the notion of nanoservices and I’ve discovered that they are good at providing logic that, maybe, doesn’t exactly fit within another service, or might be duplicated between multiple services.
I thought I’d do a walkthrough of a sample nanoservice, but, I hate contrived examples. Instead, I thought I would walk through an actual nanoservice that I wrote and plan to use for myself. To be sure, this little service is very simple, but, that makes it perfect for use as an example.
Some history before we dive in: Back in the day, Microsoft used to have a class that performed lookups between a file extension, and a mime type. In typical Microsoft fashion, they placed that class inside on of their ASP.NET assemblies and tied it directly to IIS. That meant, anyone who wanted to use that code had to pull in a bunch of ASP.NET assemblies into their project and run it on a machine with IIS. Not a big deal, I suppose, as long as the project in question was an ASP.NET website. More of a big deal though if it was, oh, say, ANYTHING besides an ASP.NET website!
Yes, believe it or not, some of us do write occasional code that doesn’t have anything to do with websites. Now, call me picky, but it always irked me to have to pull in ASP.NET assemblies, in my (for instance) WPF desktop projects, just to be able to do something that otherwise has nothing to do with websites. For instance, converting between mime types and file extensions.
So, I did what any .NET developer worth their salt would do. I created my own class to perform that conversion. Only problem was, my class was written in C#, which became an annoyance if I wanted to use that code from a non-.NET project. What’s more, my little class didn’t do important things, like keep up to date with new mime types, or remove outdated types. The problem was, my code was literally just a utility class, but it needed to be more than that.
Fast forward to today. Microservices are a thing that I use personally, as well as professionally. So, when I needed to convert between a file extension, and a mime type, in one of my microservice projects, I remembered that old utility class. I thought about pulling it into my project, but, I knew it lacked features that I wanted. I also knew that I would probably need to perform that same conversion in some of my other microservices. I thought about standing up an entire microservice for that, but that seemed like overkill. Then, along came the notion of a nanoservice. Suddenly, the idea of wrapping that old utility class in a REST API didn’t seem as nutty as it had before.
So I started looking at the idea of standing up a nanoservice to handle mime type related conversions. I didn’t need anything fancy but I did need to be able to call this service via a REST call, so I could use it in scripts, websites, microservices, desktop apps, libraries, NUGET packages, mobile applications, and so on.
I started with this architecture:
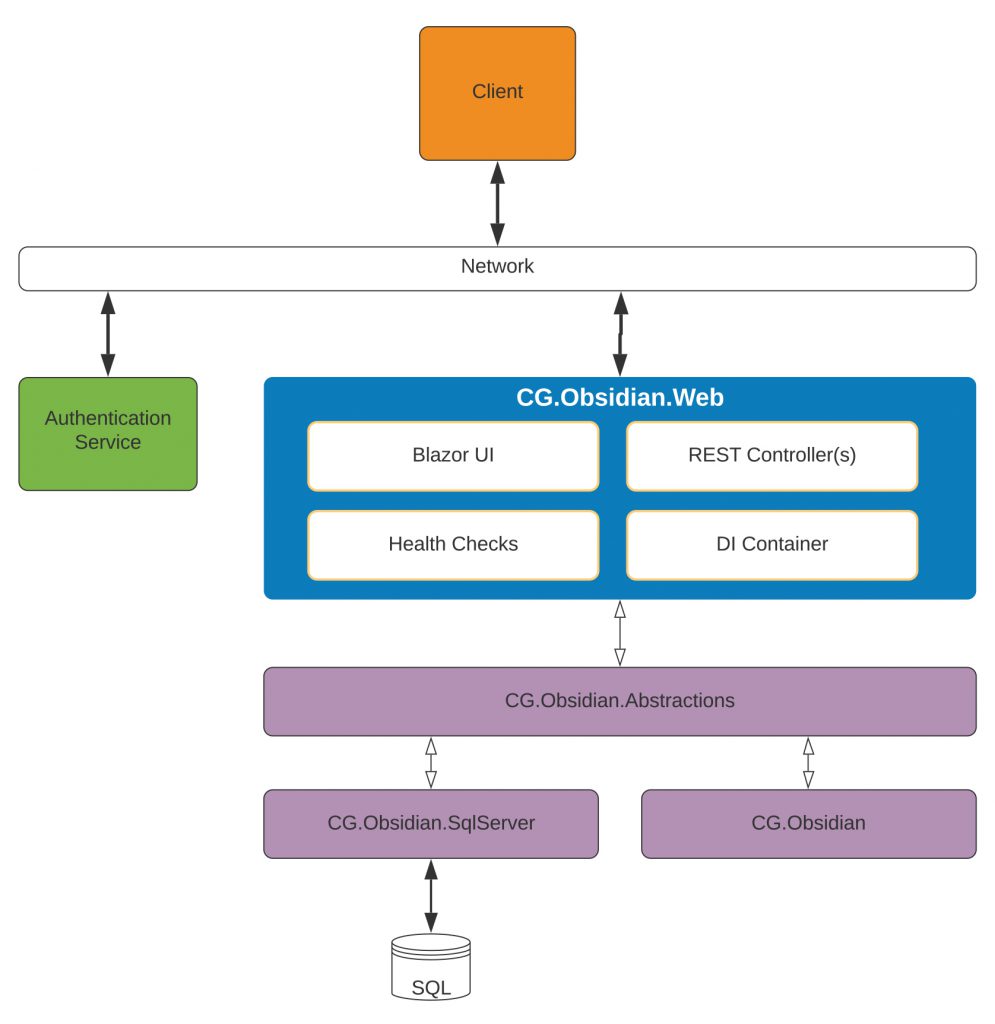
I first assumed that I would use an external source for any authentication. This is because I typically defer to my authentication microservice for such things. Also, this nanoservice would be small enough that, hauling in everything needed to locally host authentication services seemed like overkill.
Next, I assumed that any caller, for this service, would probably either make raw HTTP calls, to the microservice, or, if the caller was .NET based, then I could create a simple client library for them to use, and hide all the REST calls inside that library.
I then assumed that I would break all my actual business logic out, into at least 3 assemblies:
- A library to hold all my shared abstractions – things like models, interfaces, exceptions, etc.
- A library to hold my business logic – inside things like stores, managers, etc.
- A library to hold repository code for any given storage technology – such as Sql-Server.
After that, I was left with the nanoservice project itself, which I knew needed to contain any UI, any REST controllers, as well as other necessary things, like health checks.
This seemed like a reasonable start for my nanoservices. Next, I laid out what I knew I would need, for a database:
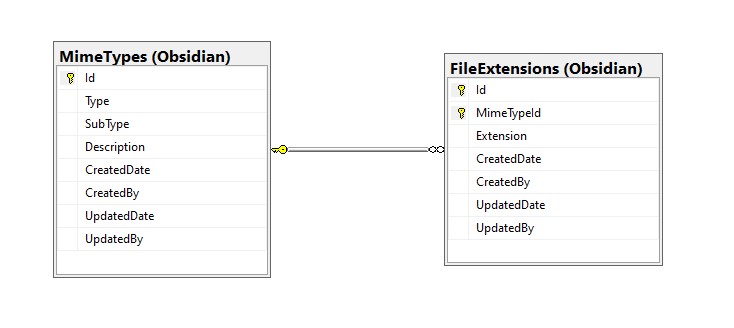
This database is simple enough to meet the current needs of the nanoservice. It contains a table for mime types, and another table for file extensions. Each mime type can have up to N file extensions. The nice thing about this approach is that it lends itself well to non-relational databases. That means, we can (eventually) look into using a no-sql database, in place of SQL-Server, to keep our hosting costs down. For now though, we’ll stand up the prototype using SQL-Server, since I have it on my development machine.
Next, I created an empty solution, in Visual Studio, and added the following projects to it:
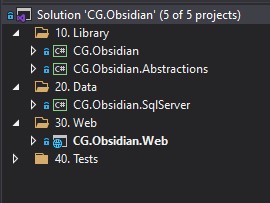
The projects all correspond to boxes on my architectural diagram.
- CG.Obsidian – contains all my business logic.
- CG.Obsidian.Abstractions – contains all my shared abstractions.
- CG.Obsidian.SqlServer – contains all the repositories and efcore related code.
- CG.Obsidian.Web – contains the nanoservice itself.
The web project started as a vanilla server-side Blazor project. Everything else started as vanilla .NET 5.x class libraries.
Eventually, I’ll add the client library. I’ll keep that library separate from the rest of this project because it will end up as a NUGET package, with it’s own CI/CD pipeline. Don’t worry though, I haven’t forgotten about the client.
That’s about it for the background and high level overview of this nanoservice. Next time, I’ll lay out the code that actually makes the service functional.
In the mean time, all of my code is available, online, HERE
Photo by Nizzah Khusnunnisa on Unsplash

